I’m a DevSecOps nerd, honestly I’ve always been a big proponant of deployment automation. For me, having git + CI/CD, that’s table stakes for any software development project. You can’t expect your developers to be productive and deliver value and bog them down with manual tasks of just getting code into new environments. It honestly doesn’t work, full stop.
So one of the first questions a team should ask (and if you aren’t, go back one space and figure this out). What’s our branching strategy going to be? The single most important thing you can figure out when you are starting a development project, especially when collaborating with other developers, is to identify how you are going to manage that git repo. When managed properly, this can accelerate your deliver of code to environments and into the hands of users. When managed poorly, this can cripple your team and cause terrible slow downs in productivity.
What is a branching strategy?
A branching strategy is an approach to how you manage not so much code in your repo, but rather changes to the code in your repo. So when we start out looking at a code repo of any kind, it’s one thing when there’s only a single developer engaged. But when you have more than that, or are considering the idea of opening that repo to the public via Open-Source on Github, you need to think of ways that developers can make sure of the following:
- How do I know I have the latest version of code?
- How do I get it next version when changes land?
- How do I track my changes?
- How do I submit my changes for inclusion?f
Git solves these problems out of the box by leveraging the concept of feature branches. The short version for those new to this concept is that every repo has a main branch, this is considered the baseline you work off of. And when you have a new feature, a bug, or a unit of work to accomplish, you would execute the following steps in sequence:
- Create a feature branch off of main, this is now your starting point.
- Perform the required work you need, make changes, test, iterate, etc.
- Create a Pull Request, which is a “request to pull your changes into main.”
- After it is reviewed and approved, the changes are merged to main.
Now all branching strategies, are based upon principles / truths that the team accepts as the baseline of the strategy. We’ll be talking more about these principles further on in this post.
General Best Practices for Git:
Now, with the above, there are lots of good practices you should adopt to make sure you are able to see the full benefits of git. Some of the big ones for me are:
- Feature Branches should be short lived: Do everything in your power to keep your feature branches short lived and PR back to main as soon as possible. The reason being, other developers are pushing their changes to main, and the longer your branch lives the harder the merge is going to be.
- Keep your work small and atomic: Another anti-pattern that happens all to often is that people create these branches that are like “kevin/sprint22_work”. This is not a good idea. The reason being is that when you do merge back to main, you will have a hard time separating out what work was related to what PR. It can also make testing and validation very difficult.
- Squash Merge to main: This one is an opinion on my side, but when you do a PR merge to main, I recommend doing a “squash merge” this creates a single commit on the main branch for your changes. The benefit to this is it keeps your branch clean and easy to read. You can avoid having the classic “Fixing typo” commit on your main branch. It makes your main branch history read like a timeline of commits.
- Use Git Tags: Another feature of git, git tags can be really useful when trying to add meta data to your repo. Things like tagging with version numbers can be critical to rolling back or forward with your code. For more information on tagging, see this in the git documentation.
Let’s set a scenario to walk through this?
When talking about code and branching, it can be really helpful to have a scenario to guide the conversation, so for the rest of this post, let’s use the following scenario:
- Our repo is “awesome-service”, and it’s a fantastic new service that is going to revolutionize the company.
- We have a development team of two, John and Jane.
- We maintain 3 separate environments, sandbox, test, and prod.
- Our dev is deployed to with any new changes to the main branch.
- We push to test at the end of every two week sprint.
- We push the contents of test to production after two weeks for our users to review. So in short:
- Dev – Changes with PR
- Test – At the end of a sprint (Say sprint 1)
- Prod – At the end of the next sprint (sprint 2)
So given the above, I’m going to walk through two potential branching strategies, and the are the following, called Classic and vNext.
What is the classic model?
So the first model we are going to evaluate is what I call the “Classic Model”, and I have this here because it’s honestly the most common branching strategy. I strongly advised against this strategy. And we’re going to walk through why, but let me outline this model here.
For this strategy, the classic branching strategy is built upon the idea that “main” is a representation of the production / stable version of the solution. So if by taking the guiding principle that main is production. It means that we would need to approach a branching strategy with the following:
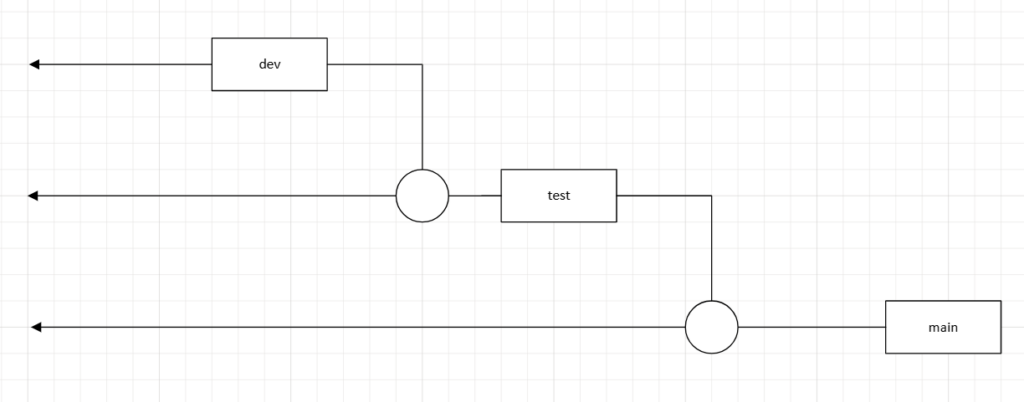
This branching strategy focuses on the idea that you would then have a branch per environment.
So given that main is production, the intention is then to create a long-lived branch for each environment. If a developer wants to make changes, they would then open a feature branch off the “dev” to make their changes as shown below:
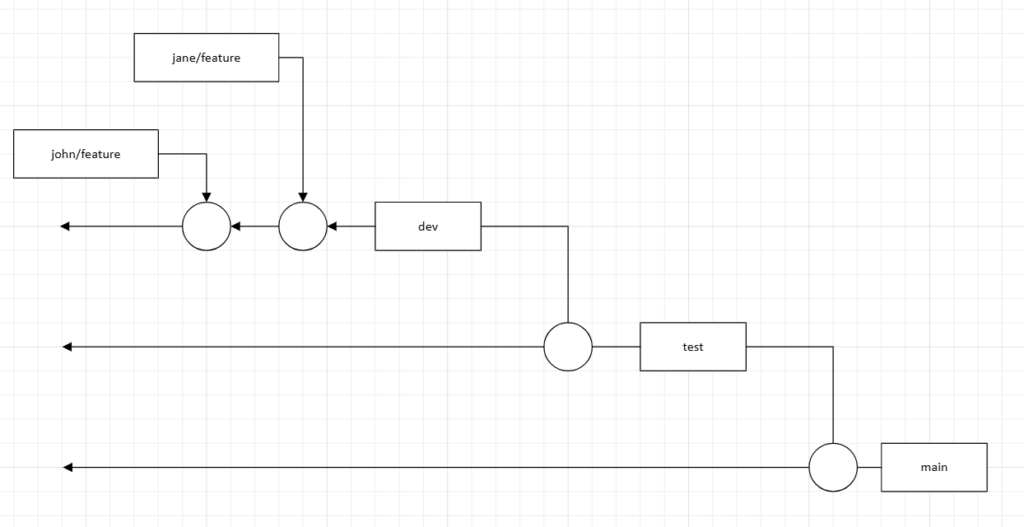
The intention then being that when prior to performing a deployment from to an environment, you would perform a PR pulling into the environment.
What are the draw backs of the classic model?
This classic branching strategy was really built around waterfall, and the approach of saying the focus is on production. There are a couple of fundamental problems with this approach that in a modern agile development process cause lots of issues.
The problems are the following:
- Focus is off of the work: The biggest problem I have with this approach is that it puts the focus on tracking the current version in production as the focus of the repo. Developers are always working on vNext, not the current production version. Classic makes it more complicated for developers to do their day-to-day work.
- Agile Deployments add overhead: When you are deploying via this strategy, you are adding additional complexity to the process by forcing activities to be managed via the repo related to deployment. In classic when you cut a PR from Dev -> Test, or Test -> Prod, you are in essence requiring someone to perform a full code review of the release before it goes to an environment. That is not realistic and all to often I find gets “rubber stamped” to move forward.
- Long Lived Branches create challenges: For this strategy, you have 3 branches that are going to live forever, and as such can get stale or fall out of sync with environments.
- Hot Fixes are a lot more complicated: If you use this strategy/model, and let’s say there is a CVE that requires a fix to production, and you make the change to main. You then must reverse integrate and duplicate that change back through each environment driven branch. So make the same change in test, then in dev and test and validate at each level. This makes hotfixes very painful.
- No ability to trace changes to features on main: Using this approach, you are now bundling all changes into monster PRs that are moving from Dev -> Test, and Test -> Prod. This means in the future if you want to see what items code changes related to what feature? You have to pull apart single commits, which is a nightmare.
- Makes Environments Static: When you align branches to this, if the business has the need to add a new environment, that is a serious problem. Let’s say the business asks for a pre-prod environment? Or they want a new environment for a subset of users to test a new feature? You have a tight coupling between each of these branches that make it impossible to insert a new environment into the flow.
What is the vNext model?
Alright, let’s talk the vNext strategy / model, and it’s implementation. The core principles/ truthes behind this approach are:
- Main is vNext, or the bleeding edge next version of the service.
- Environments exist as something separate from code, we prioritize managing versions and their history.
So how does this stategy / model work with our scenario, the steps are the following:
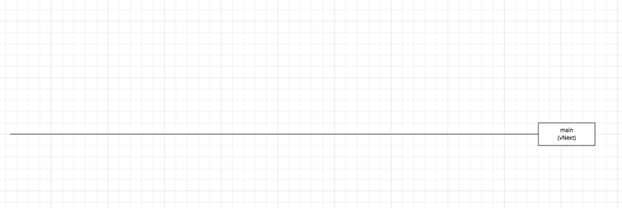
We start with our main branch, and by default when the first line of code is written, this represents our next release.
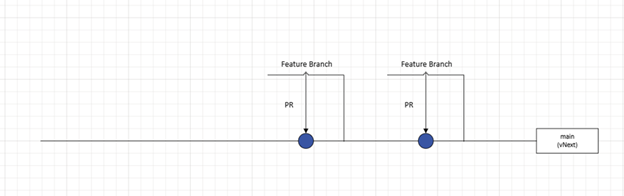
Now as our developers begin to work on the first version, they are going to create feature branches off main. The recommendation here being that we would perform “squash merges” to push to main. This ensures that we have a clean history of changes as they relate to features and units of work moving forward.
Now, when we get to the point of deploying our code. We can have pipelines or workflows wired up to push our code to dev, or any environment based on deployment conditions. But when it comes time to cut a release, we would create a git tag marking the release.
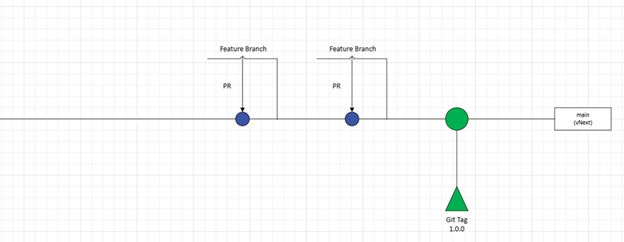
NOTE: And I would also recommend that if you are deploying to an environment, that your workflow / pipeline add a git tag here showing that the deployment happened. Use any schema you want, but I recommend “env-dev-04.28.2025”, so that when you examine commits you can see, “This is version 1.0.0, and it was released to dev on 4/28/2025.”
From there, the vNext strategy would say, you create a hotfix branch for 1.0.0, similar to what’s shown below:
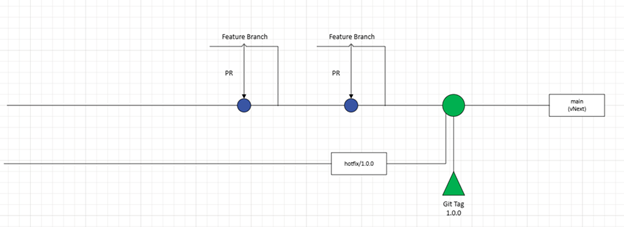
The intention of this hotfix branch is to provide an easy “in-case-of-emergency-break-glass” option should there need to be an update to the version. If that event should arise, the process would be to have the developer working on the patch, open a “feature branch” or “patch branch” off of “hotfix/1.0.0” as shown below:
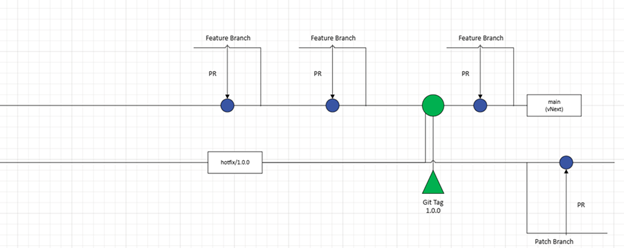
Now, when the changes are complete for the patch, you can then perform a PR against “hotfix/1.0.0”, and then reverse integrate the changes back into “main” so that you gain the benefit in vNext. I would also recommend adding a git tag, marking this as “1.0.1” and incrementing the appropriate patch number on main for vNext.
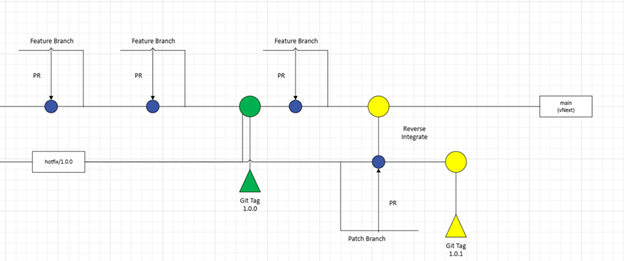
Now when it comes to cutting your “1.1.0” release, of the service, you would repeat the process from earlier:
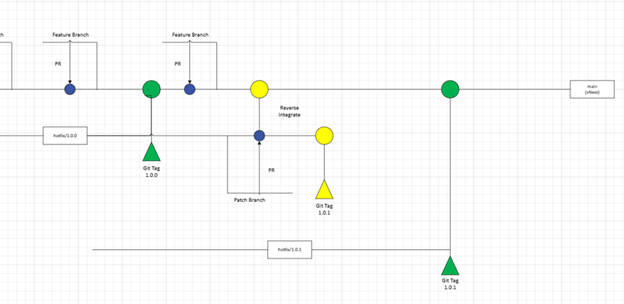
Do we delete “hotfix/1.0.0” when we cut “hotfix/1.1.0”? The answer here is “it depends”, and the reason for that is it depends on what your team is currently supporting. Is this being offered as a service via a managed evironment? Do you have customers running older versions. The simple answer is that each hotfix branch lives exactly as long as you support that version…period. So if you are using environments like we outlined above, that would mean that you would likely have 2 hotfix branches running at any given moment.
- Dev = main / vNext
- Test = hotfix / n – 1 (this example hotfix/1.1.0)
- Prod = hotfix / n – 2 (this example hotfix/1.0.0)
But the benefits to this strategy / model are numerous, but to highlight a few:
- Focus is on the work: This model focuses the branching strategy around the day-to-day work of the devs working in the environment. Making it much easier to follow.
- Deployment and Code Management are separate: You have eliminated the need to promote code through different environments and are instead working on versions not trusting that your environments are in line with versions.
- Only branch that lives forever is main: All branches, whether features or hotfixes have an end-date attached to them.
- Hot fixes are clear and easy to execute: By eliminating the unnecessary levels of promoting code through environment specific branches, hotfixes can be applied and integrated quickly without causing a derailment of the team.
- Main contains a lot of features and deployments: Using tags we gain the benefits of seeing a true history of the code throughout the entire history on the main branches.
- Environments are now decoupled from code: Really from the repo, we are managing versions of code and tracking where we deployed it which is much more accurate, and true to reality.